
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- GRU
- Sort
- tensorflow
- collections
- 딥러닝
- yarn
- NumPy
- HelloWorld
- codingthematrix
- 선형대수
- 주식분석
- hadoop2
- hive
- 하이브
- C
- 코딩더매트릭스
- 하둡2
- RNN
- 그래프이론
- python
- scrapy
- 파이썬
- 텐서플로
- graph
- C언어
- effective python
- recursion
- Java
- 알고리즘
- LSTM
- Today
- Total
목록Study (184)
EXCELSIOR
 04. 인공신경망 - Artificial Neural Networks
04. 인공신경망 - Artificial Neural Networks
이번 포스팅은 핸즈온 머신러닝 교재를 가지고 공부한 것을 정리한 것입니다. Artificial Neural Networks인공 신경망(ANN, Aritificial Neural Networks)은 1943년 신경생리학자 Warren McCulloch과 수학자 Walter Pitts가 'A Logical Calculus of Ideas Immanent In Nervous Activity' 처은 소개했으며, 명제 논리(propositional logic)를 사용해 동물 뇌의 생물학적 뉴런이 복잡한 계산을 위해 어떻게 상호작용하는지에 대해 간단한 계산 모델을 제시했다. 1960년대까지는 이렇게 등장한 인공 신경망을 통해 사람들은 지능을 가진 기계와 대화를 나눌 수 있을 것이라고 생각했다. 하지만 아래 그림(출..
 03. 오차역전파 - BackPropagation
03. 오차역전파 - BackPropagation
이번 포스팅은 '밑바닥부터 시작하는 딥러닝' 교재로 공부한 것을 정리한 것입니다. 아래의 이미지들은 해당 교재의 GitHub에서 가져왔으며, 혹시 문제가 된다면 이 포스팅은 삭제하도록 하겠습니다.. ㅜㅜ 오차역전파법 Backpropagation신경망 학습에서는 가중치 매개변수의 기울기를 미분을 이용해 구했다. 이러한 방법은 간단하지만 시간이 오래 걸리는 단점이 있다. 이번 포스팅에서는 가중치 매개변수의 기울기를 효율적으로 계산하는 오차역전파법(backpropagation)에 대해 알아보도록 하자. 1. 계산 그래프계산 그래프(computational graph)는 계산 과정을 그래프로 나타낸 것이며, 노드(node)와 엣지(edge)로 표현된다. 노드는 연산을 정의하며, 엣지는 데이터가 흘러가는 방향을 ..
 02. 신경망 학습 (1)
02. 신경망 학습 (1)
이번 포스팅은 '밑바닥부터 시작하는 딥러닝' 교재로 공부한 것을 정리한 것입니다.신경망 학습이번 포스팅에서는 신경망 학습(training)에 대해 알아보자. 학습이란 학습 데이터로부터 가중치 매개변수의 최적값을 자동으로 찾는것을 말한다. 또한, 이번 장에서는 신경망이 학습할 수 있도록 하는 지표에 해당하는 손실함수 에 대해 알아보자. 1. 데이터 주도 학습1.1 데이터 주도 학습딥러닝을 종단간 기계학습(end-to-end machine learning)이라고도 한다. 종단간은 ‘처음부터 끝까지’라는 의미로, 데이터(입력)에서 목표한 결과(출력)를 얻는다는 뜻을 담고 있다. (그림 출처: 밑바닥부터 시작하는 딥러닝) 1.2 훈련 데이터와 시험 데이터머신러닝과 딥러닝에서는 데이터를 훈련 데이터(trainin..
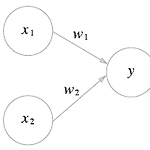 01. 퍼셉트론 - Perceptron
01. 퍼셉트론 - Perceptron
이번 포스팅은 '밑바닥 부터 시작하는 딥러닝'교재로 공부한 것을 정리했습니다. 퍼셉트론 - Perceptron 1. 퍼셉트론이란?퍼셉트론(perceptron)은 프랑크 로젠블라트(Fank Rosenblatt)가 1957년에 고안안 알고리즘이다. 이 퍼셉트론이 바로 신경망(딥러닝)의 기원이 되는 알고리즘이다.퍼셉트론은 다수의 신호(흐름이 있는)를 입력으로 받아 하나의 신호를 출력한다. 퍼셉트론은 이 신호를 입력으로 받아 '흐른다/안 흐른다'(1 또는 0)이라는 정보를 앞으로 전달한다. 위의 그림에서,과 는 입력 신호, 는 출력 신호, 과 는 가중치(weight)를 의미한다. 원을 뉴런 또는 노드라고 부른다.입력 신호가 뉴런에 보내질 때는 각각 고유한 가중치가 곱해진다().뉴런에서 전달 받은 신호..
 차원 축소 - LLE (2)
차원 축소 - LLE (2)
차원 축소 - Locally Linear Embedding (LLE)이번 포스팅은 Nonlinear Dimensionality Reduction by Locally Linear Ebedding (Roweis et.al) 논문과 핸즈온 머신러닝 교재를 가지고 공부한 것을 정리한 것입니다. 1. LLE - Locally Linear Embedding 란?LLE(Locally Liner Embedding, 지역 선형 임베딩)는 Nonlinear Dimensionality Reduction by Locally Linear Ebedding (Roweis et.al) 논문에서 제안된 알고리즘이다. LLE는 비선형 차원 축소(NonLinear Dimensionality Reduction, NLDR) 기법으로 '차원 ..
 차원 축소 - PCA, 주성분분석 (1)
차원 축소 - PCA, 주성분분석 (1)
차원 축소 - PCA (1)대부분 실무에서 분석하는 데이터는 매우 많은 특성(feature)들을 가지고 있다. 이러한 데이터를 가지고 머신러닝 알고리즘을 적용해 문제를 해결하려고 한다면, 데이터의 차원이 크기 때문에 학습 속도가 느릴 뿐만아니라 성능 또한 좋지 않을 가능성이 크다. 이번 포스팅에서는 데이터의 차원을 축소하는 방법인 투영(projection)과 매니폴드 학습(manifold learning) 그리고 대표적인 차원 축소 알고리즘인 주성분분석(PCA)에 대해 알아보도록 하자. 1. 차원의 저주 머신러닝에서 데이터 셋의 특성(feature)가 많아지면, 각 특성인 하나의 차원(dimension) 또한 증가하게 된다. 이렇게 데이터의 차원이 증가할 수록 데이터 공간의 부피가 기하 급수적으로 증가하..
 서포트 벡터머신, SVM - (2)
서포트 벡터머신, SVM - (2)
이번 SVM 관련 포스팅은 '오일식 저, 패턴인식' 교재와 '핸즈온 머신러닝' 그리고 'ratsgo' 블로그를 참고하여 작성하였습니다. SVM에 대해 간략하게 알고 싶으신 분들은 여기를 참고하시면 됩니다.SVM 이란?SVM(Support Vector Machine)은 러시아 과학자 Vladimir Vapnik가 1970년대 후반에 제안한 알고리즘으로, 그 당시에는 크게 주목 받지 못했다. 하지만 1990년대에 들어 분류(classification)문제에서 우수한 일반화(generalization) 능력이 입증되어 머신러닝 알고리즘에서 인기 있는 모델이 되었다고 한다. 그리고 SVM은 일반화 측면에서 다른 분류 모델과 비교하여 더 좋거나 대등한 것으로 알려져 있다.또한, SVM은 선형 또는 비선형 분류 뿐..
Chap02 - 시퀀스 An array of sequences파이썬에서 제공하는 다양한 시퀀스를 이해하면 코드를 새로 구현할 필요가 없으며, 시퀀스의 공통 인터페이스를 따라 기존 혹은 향후에 구현될 시퀀스 자료형을 적절히 지원하고 활용할 수 있게 API를 정의할 수 있다. 2.1 내장 시퀀스 개요파이썬은 C로 구현된 다음과 같은 시퀀스들을 제공한다.컨테이너 시퀀스 : 서로 다른 자료형의 항목들을 담을 수 있는 list, tuple, collections.deque 형태균일 시퀀스 : 하나의 자료형만 담을 수 있는 str, bytes, memoryview, array.array 형태 컨테이너 시퀀스(container sequence)는 객체에 대한 참조를 담고 있으며 객체는 어떠한 자료형도 될 수 있다. ..