| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- hive
- scrapy
- C
- 하둡2
- hadoop2
- graph
- 하이브
- Java
- NumPy
- 주식분석
- 코딩더매트릭스
- 선형대수
- 파이썬
- python
- RNN
- HelloWorld
- 딥러닝
- effective python
- C언어
- tensorflow
- 알고리즘
- collections
- Sort
- GRU
- 그래프이론
- 텐서플로
- yarn
- recursion
- codingthematrix
- LSTM
- Today
- Total
EXCELSIOR
SQL-On-Hadoop(SQL-온-하둡) 개념 및 종류 본문
1. SQL-On-Hadoop 이란?
SQL-On-Hadoop이란 HDFS에 저장된 데이터에 대한 SQL 질의 처리를 제공하는 시스템을 의미한다. 대부분의 SQL-On-Hadoop 시스템들은 하둡1에서 제공하는 맵리듀스 아키텍처를 이용하지 않고 새로운 분산 처리 모델과 프레임워크를 기반으로 구현돼 있다.
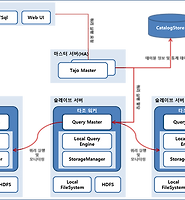
SQL-On-Hadoop에는 하이브(Hive), 타조(Tajo), 임팔라(Impala), Facebook의 프레스토(Presto) 등 다양한 SQL-On-Hadoop이 존재한다.
SQL-On-Hadoop이 출시된 배경은 다음과 같다.
- 하둡을 도입한 사용자들의 요구사항이 단순히 대용량의 데이터를 배치 처리하는 것이 아니라 높은 처리 성능과 빠른 반응속도를 요구하고 있다. 데이터 분석 과정에서 다양한 쿼리를 반복해서 실행하기 위해 높은 성능을 요구했던 것이다.
- SQL은 사용자가 이해하기 쉬운 단어로 구성되어 있어 Java에 익숙하지 않은 데이터 분석가들이 손쉽게 데이터를 처리할 수 있다.
- 쿼리 성능 보장과 사람에 의해 발생하는 오류를 방지하기 위해서이다. 맵리듀스 프로그램의 품질은 개발자의 역량에 좌우되며, 프로그램에 버그가 있을 경우 발견하기도 힘들기 때문이다.
2. SQL-On-Hadoop 분류 기준
1) Interactive Query vs. Long Time Query
인터랙티브 쿼리는(Interactive Query)는 밀리초 혹은 수 초내에 끝날 수 있는 Short Time Query이며, 이는 low latency를 지원한다고 말한다. 반대로 Long Time Query는 쿼리를 실행하는데 오랜 시간 소요되는 쿼리를 의미한다.
Long Time Query의 지원 여부는 처리하고자 하는 데이터 크기에도 영향을 받는다. 데이터 처리를 빠르게 하는 방법 중 하나는 캐시나 메모리에 데이터를 로딩하는 것이다. 이때 원 본 데이터의 크기가 메모리보다 크면 쿼리를 처리할 수 없거나 다른 방법으로 쿼리를 실행해야 한다. Long Time Query는 TB ~ PB이상의 데이터를 지원할 수 있다.
Long Time Query를 지원하려면 내고장성(Fault Tolerance), 다이나믹 스케줄링 두가지 설계 포인트가 있다.
내고장성(Fault Tolerance)
SQL-On-Hadoop에서 내고장성이란 쿼리 처리 중 발생하는 오류를 처리해 쿼리를 완료하는 기능을 의미한다. Long Time Query는 수십 분에서 수 시간 이상이 소요된다. 이러한 쿼리는 작은 단위의 태스크로 나누어 처리하고, 오류의 범위를 해당 태스크로 한정한 후, 태스크를 재시작해야 한다. 내고장성을 지원할 경우 쿼리 처리 중간에 생성되는 데이터를 병합해야 하는데, 디스크 부하를 야기할 수 있다. 따라서 내고장성과 시스템의 처리량(Throughput)은 Trade-off 관계라고 할 수 있다.
다이나믹 스케줄링(Dynamic Scheduling)
스케줄링 기법에는 고정 스케줄링(Fixed Scheduling)과 다이나믹 스케줄링(Dynamic Scheduling)이 있다. 고정 스케줄링은 작업을 시작할 때 클러스터 노드에게 균등하게 분할된 작업을 한 번에 할당한다. 하지만 다이나믹 스케줄링은 각 노드에 노드가 한 번에 실행할 수 있는 태스크를 우선적으로 분배한다. 그리고 노드가 할당받은 태스크가 완료되면 다시 태스크를 할당한다.
아래의 표는 타조, 임팔라, 하이브, 프레스토의 4가지 특성을 비교한 표이다.
System Name | Fault Tolerance | Dynamic Scheduling | Long Time Query | Low Latency |
Tajo(타조) | O | O | O | O |
Impala(임팔라) | X | X | X | O |
Hive(하이브) | O | O | O | O |
Presto(프레스토) | X | X | X | O |
2) Data Warehouse Infrastructure vs. Distributed Query Engine
Long Time Query 지원 여부는 해당 시스템이 데이터 웨어하우스 인프라스트럭처(Data Warehouse Infrastructure)에 적합한 시스템인지, 아니면 빠른 쿼리만을 처리하기 위한 분산 쿼리 엔진(Distributed Query Engine)인지를 결정한다.
아래의 표는 두 시스템의 차이를 나타낸 표이다.
Data Warehouse Infrastructure |
Distributed Query Engine |
|
|
'DataBase > Hadoop' 카테고리의 다른 글
| Hadoop2(하둡2)설치 - 완전분산모드 & 네임노드 HA구성 (7) | 2017.01.21 |
|---|---|
| Apache Tajo (아파치 타조) 개념 및 설치 (0) | 2016.12.12 |
| 스쿱(sqoop)과 MS-SQL 연동하기 (0) | 2016.12.08 |
| 스쿱(sqoop) 설치 (0) | 2016.12.07 |
| 아파치 스쿱(Apache Sqoop) (1) | 2016.12.07 |