
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 주식분석
- codingthematrix
- hadoop2
- NumPy
- GRU
- graph
- Java
- 선형대수
- C
- 그래프이론
- tensorflow
- 딥러닝
- yarn
- 알고리즘
- RNN
- hive
- collections
- Sort
- LSTM
- python
- HelloWorld
- recursion
- 코딩더매트릭스
- 하둡2
- 파이썬
- 하이브
- C언어
- 텐서플로
- effective python
- scrapy
- Today
- Total
EXCELSIOR
머신러닝의 정의 및 분류 본문
1. 정의
1) 카네기멜론 대학교의 톰 미첼(Tom Mitchell) 교수는 [머신러닝] 이라는 저서에서 다음과 같이 정의 했다.
" 만약 컴퓨터 프로그램이 특정한 태스크 T를 수행할 때 성능 P 만큼 개선되는 경험 E를 보이면 그 컴퓨터 프로그램은 태스크와 성능 P에 대해 경험 E를 학습했다라고 할 수 있다."
예를 들어, 컴퓨터에 필기체를 인식하는 학습을 시킨다고 했을 때,
① 태스크 T : 필기체를 인식하고 분류하는 것
② 성능 P : 필기체를 정확히 구분한 확률
③ 학습 경험 E: 필기체와 정확한 글자를 표시한 데이터 셋
2) 실무에서는 다음과 같이 정의할 수 있다.
"학습(Learning) = 표현(representation) + 평가(evaluation) + 최적화(optimization)"
① 표현 : 태스크를 수행하는 에이전트가 입력값을 처리해 어떻게 결과값을 만들지를 결정하는 방법 (ex. 필기체 숫자가 실제로 어떤 숫자를 의미하는지 예측하는 모형)
② 평가 : 에이전트가 얼마만큼 태스크를 잘 수행했는지 판정하는 방법을 말함
③ 최적화 : 평가에서 설정한 기준을 최적으로 만족하는 조건을 찾는 것
④ 일반화 : 새로운 데이터에 대한 예측을 하는 것
[출처 : 김의중 저. 알고리즘으로 배우는 인공지능, 머신러닝, 딥러닝 입문. 위키북스]
2. 분류
머신러닝은 학습 데이터에 레이블(Label) 있는 경우와 없는 경우에 따라 지도학습(Supervised Learning) 과 비지도 학습(Unsupervised Learning) 으로 나뉜다.
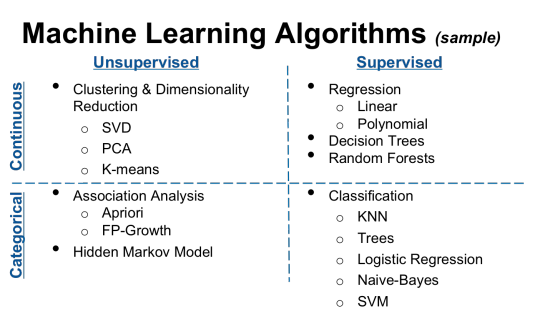
Supervised Learning vs Unsupervised Learning
3. 기계학습과 통계학의 차이
통계학이 가설을 검증하는 일과 더 밀접하게 관련돼 있는 반면, 기계학습은 가설을 통해 일반화한 프로세스를 공식화하는 작업에 좀 더 연관돼 있다.
'Machine_Learning(ML)' 카테고리의 다른 글
| TextRank를 이용한 문서요약 (26) | 2017.06.12 |
|---|---|
| Support Vector Machine (SVM, 서포트 벡터 머신) (0) | 2017.01.05 |
| 로지스틱 회귀 (Logistic Regression) (2) | 2016.12.03 |
| 규칙기반학습(Rule-Based Learning) (2) | 2016.11.27 |
| Naive Bayes Classifier (0) | 2016.11.26 |


