| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 그래프이론
- LSTM
- 주식분석
- tensorflow
- GRU
- HelloWorld
- RNN
- graph
- Sort
- collections
- 하둡2
- 파이썬
- scrapy
- effective python
- python
- NumPy
- 선형대수
- C언어
- yarn
- 텐서플로
- hadoop2
- C
- 알고리즘
- 하이브
- codingthematrix
- 딥러닝
- Java
- recursion
- 코딩더매트릭스
- hive
- Today
- Total
EXCELSIOR
04. 인공신경망 - Artificial Neural Networks 본문
이번 포스팅은 핸즈온 머신러닝 교재를 가지고 공부한 것을 정리한 것입니다.
Artificial Neural Networks
인공 신경망(ANN, Aritificial Neural Networks)은 1943년 신경생리학자 Warren McCulloch과 수학자 Walter Pitts가 'A Logical Calculus of Ideas Immanent In Nervous Activity' 처은 소개했으며, 명제 논리(propositional logic)를 사용해 동물 뇌의 생물학적 뉴런이 복잡한 계산을 위해 어떻게 상호작용하는지에 대해 간단한 계산 모델을 제시했다.
1960년대까지는 이렇게 등장한 인공 신경망을 통해 사람들은 지능을 가진 기계와 대화를 나눌 수 있을 것이라고 생각했다. 하지만 아래 그림(출처: beamandrew's blog)처럼 사람들의 기대와는 달리 인공 신경망으로 XOR문제를 해결할 수 없게 되었고, 1990년 대에는 SVM과 성능이 좋은 다른 머신러닝 알고리즘들이 나오게 되면서 인공 신경망은 암흑기로 접어 들게 되었다.

2000년 대에 들어서면서 인공 신경망은 2012년 ILSVRC2012 대회에서 인공 신경망을 깊게 쌓은 딥러닝 모델인 AlexNet이 압도적인 성적으로 우승하면서 다시금 주목받게 되었다. 이렇게 인공 신경망(딥러닝)이 다시 주목받게 된 계기는 다음과 같은 것들이 있다.
빅 데이터 시대인 요즘 신경망을 학습시키기 위한 데이터가 엄청나게 많아 졌다.
신경망은 다른 머신러닝 알고리즘보다 규모가 크고 복잡한 문제에서 성능이 좋다.
1990년대 이후 크게 발전된 컴퓨터 하드웨어 성능과 Matrix연산에 고성능인 GPU로 인해 상대적으로 짧은 시간 안에 대규모의 신경망을 학습시킬 수 있게 되었다.
1 뉴런
1.1 생물학적 뉴런
인공 뉴런에 대해 살펴보기 전에 생물학적 뉴런을 먼저 살펴보도록 하자. 아래의 그림(출처: wikipedia)은 사람의 뇌에서 볼 수 있는 세포로써 핵(nucleus)을 포함하는 세포체(cell body)와 구성 요소로 이루어져 있다.
Dendrite : 수상돌기, 다른 뉴런으로부터 신호를 수용하는 부분
Axon : 축삭돌기, 신호를 내보내는 부분
Synaptic terminals : 시냅스(synapse) 뉴런의 접합부, 다른 뉴런으로 부터 짧은 전기 자극 신호(signal)를 받음

1.2 최초의 인공 뉴런
처음 인공 신경망을 제안한 Warren McCulloch과 Walter Pitts의 인공 뉴런 모델은 아래의 그림(출처: 핸즈온-머신러닝)과 같다. 이 모델은 하나 이상의 이진(on/off) 입력과 하나의 출력을 가진다.

①은 항등함수를 의미하며, 뉴런
A가 활성화 되면 뉴런C또한 활성화된다.②는 논리곱 연산을 의미하며, 뉴런
A와B가 모두 활성화될 때만 뉴런C가 활성화된다.③은 논리합 연산을 의미하며, 뉴런
A와B둘 중 하나라도 활성화되면C가 활성화된다.④는 어떤 입력이 뉴런의 활성화를 억제할 수 있다고 가정하면, 위의 그림에서 처럼 뉴런
A가 활성화 되고B가 비활성화될 때 뉴런C가 활성화된다.
2. 퍼셉트론
퍼셉트론(Perceptron)은 Frank Rosenblatt가 1975년에 제안한 인공 신경망 구조 중 하나이며, 이 퍼셉트론이 바로 신경망(딥러닝)의 기원이 되는 알고리즘이라고 할 수 있다. 퍼셉트론에 대한 자세한 내용은 여기서 확인할 수 있다.
퍼셉트론은 TLU(Threshold Logic Unit)이라는 형태의 뉴런을 기반으로 하며, 아래의 그림과 같이 입력과 출력이 어떤 숫자고 각각의 입력에 각각 고유한 가중치(, weight)가 곱해진다.
그런 다음 계산된 합 에 계단 함수(step function)를 적용하여 결과 를 출력한다.

퍼셉트론에서 가장 널리 사용되는 계단 함수는 헤비사이드 계단 함수(Heaviside step function)이며, 단위 계단 함수(unit step function)라고도 한다. 간혹 계단 함수 대신 부호 함수(sign function)을 사용하기도 한다.
위의 그림에서 처럼, 하나의 TLU는 입력과 가중치의 선형결합인 가 이면 양성 클래스, 이면 음성 클래스를 출력하게 하는 선형 이진 분류(linear binary classification)에 적용할 수 있다. 이러한 TLU를 학습시킨다는 것은 분류를 잘할 수 있는 최적의 매개변수 을 찾는다는 뜻이다.
아래의 그림은 위의 TLU를 세 개로 구성한 퍼셉트론에 편향()을 추가한 것이다. 이 퍼셉트론은 샘플 세 개의 클래스(레이블)로 분류할 수 있는 Multioutput Classifier이다.

2.1 퍼셉트론 학습
Frank Rosenblatt가 제안한 퍼셉트론의 학습 알고리즘은 헤브의 규칙(Hebb's rule)로 부터 영감을 받았다. Donald Hebb는 1949년에 출간한 책 'The Organization of Behavior'에서 뉴런이 다른 뉴런을 활성화시킬 때 이 두 뉴런의 연결이 강해진다고 주장했다. 즉, 두 뉴런이 동일한 출력을 낼 때마다 이 둘 사이의 연결 가중치가 증가하며 이러한 규칙을 헤브의 규칙 또는 헤브 학습(Hebbian Learning)이라고 한다. 퍼셉트론은 네트워크가 만드는 에러를 반영하도록 학습되며 잘못된 출력을 만드는 연결은 올바른 출력을 만들 수 있도록 가중치를 조정한다.
예를 들어 하나의 데이터 샘플이 퍼셉트론에 입력되면 각 샘플에 대해 출력(예측)이 만들어지고, 잘못된 예측을 하는 모든 출력 뉴런에 대해 올바른 예측을 만들 수 있도록 아래의 식과 같이 입력에 연결된 가중치를 강화한다.
: -번째 입력 뉴런과 -번째 출력 뉴런 사이를 연결하는 가중치
: 현재 학습 데이터 샘플의 -번째 뉴런의 입력값
: 현재 학습 데이터 샘플의 -번째 출력 뉴런의 출력값
: 현재 학습 데이터 샘플의 -번째 출력 뉴런의 실제값
: 학습률, learning rate
Frank Rosenblatt는 학습 데이터가 선형적으로 구분될 수 있으면, 퍼셉트론은 정답에 수렴한다는 것을 보였는데 이를 퍼셉트론 수렴 이론(Perceptron convergence theorem)이라 한다. 하지만, 출력 뉴런의 decision boundary는 선형(결합)이므로 퍼셉트론은 복잡한 패턴 (e.g. 비선형)은 학습하지 못한다.
2.2 Scikit-Learn의 Perceptron 클래스
Scikit-Learn은 하나의 TLU 퍼셉트론을 구현한 Perceptron 클래스를 제공한다. 아래의 예제는 iris dataset(붓꽃 데이터셋)에서 꽃잎의 길이(petal length)와 너비(petal width)를 가지고 붓꽃 종류 중 Setosa인지 아닌지를 분류하는 이진 분류기를 구현한 것이다.
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
iris = load_iris()
X = iris.data[:, (2, 3)] # petal length, width
y = (iris.target == 0).astype(np.int)
per_clf = Perceptron(max_iter=100, random_state=42)
per_clf.fit(X, y)Perceptron(alpha=0.0001, class_weight=None, eta0=1.0, fit_intercept=True,
max_iter=100, n_iter=None, n_jobs=1, penalty=None, random_state=42,
shuffle=True, tol=None, verbose=0, warm_start=False)
y_pred = per_clf.predict([[2, 0.5]])
print(y_pred)a = -per_clf.coef_[0][0] / per_clf.coef_[0][1]
b = -per_clf.intercept_ / per_clf.coef_[0][1]
axes = [0, 5, 0, 2]
x0, x1 = np.meshgrid(
np.linspace(axes[0], axes[1], 500).reshape(-1, 1),
np.linspace(axes[2], axes[3], 200).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = per_clf.predict(X_new)
zz = y_predict.reshape(x0.shape)
plt.figure(figsize=(10, 4))
plt.plot(X[y==0, 0], X[y==0, 1], "bs", label="Iris-Setosa 아님")
plt.plot(X[y==1, 0], X[y==1, 1], "yo", label="Iris-Setosa")
plt.plot([axes[0], axes[1]], [a * axes[0] + b, a * axes[1] + b], "k-", linewidth=3)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#9898ff', '#fafab0'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
plt.xlabel("꽃잎 길이", fontsize=14)
plt.ylabel("꽃잎 너비", fontsize=14)
plt.legend(loc="lower right", fontsize=14)
plt.axis(axes)
plt.show()
2.3 퍼셉트론의 약점: XOR 문제
1969년 Marvin Minsky와 Seymour Papert는 '퍼셉트론'이란 논문에서 퍼셉트론의 심각한 약점이 있다는 것을 보였는데, 그 중에서도 가장 결정적인 것은 선형결합인 퍼셉트론이 배타적 논리합인 XOR 분류 문제를 해결할 수 없다는 것이었다.

이를 계기로 인공 신경망은 암흑기를 맞이하게 되었다. 하지만, 단일 퍼셉트론을 여러개 쌓아 다층 퍼셉트론(MLP, Multi-Layer Perceptron)을 통해 XOR 분류 문제를 해결할 수 있었다.

2.4 다층 퍼셉트론과 역전파
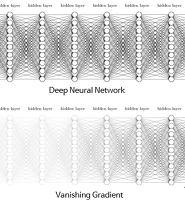
위에서 살펴 봤듯이 다층 퍼셉트론(MLP)은 아래의 그림과 같이 입력층, 은닉층(hidden layer)이라 부르는 하나 이상의 TLU 층과 마지막으로 출력층(output layer)으로 구성된다. 인공 신경망의 은닉층이 2개 이상일 때, 심층 신경망(DNN, Deep Neural Network)라 하고 이를 학습하여 모델을 만드는 것을 우리가 익히 들어온 딥러닝(Deep-Learning) 이라고 한다.

이렇게 여러층을 쌓은 MLP를 통해 XOR 문제를 해결 했지만, 층이 깊어질 수록 증가하는 가중치 매개변수의 수로 인해 다층 퍼셉트론을 학습시키기에는 오랜 시간이 걸리는 문제가 발생했다. 하지만, 1986년 역전파(backpropogation) 알고리즘이 등장하면서 계산량을 획기적으로 줄일 수 있게 되었다. 역전파법에 대한 자세한 내용은 여기를 참고하면 된다.
역전파법을 간단히 설명 한다면 다음과 같다.
먼저, 각 학습 데이터 샘플을 네트워크에 입력으로 넣어주고 출력층까지 각 층의 뉴런 마다 출력을 계산한다. 이를 순전파(forward propagation)이라고 한다.
그 다음 네트워크의 마지막 출력층에 대한 결과(예측값)와 실제값과의 차이, 즉 오차(error)를 계산하는데, 손실함수(loss function)를 이용하여 계산한다.
그리고 이 오차를 역방향으로 흘러 보내면서, 각 출력 뉴런의 오차에 마지막 입력 뉴런이 얼마나 기여했는지 측정한다. 이말을 쉽게 설명하면, 각 뉴런의 입력값에 대한 손실함수의 편미분, 그래디언트(gradient)을 계산하는 것을 말한다.
3번과 같은 방법을 입력층에 도달할 때까지 계속 반복해서 역방향으로 흘러 보낸다.
마지막으로, 계산한 그래디언트를 네트워크의 모든 가중치 매개변수에 반영해주는 경사 하강법 단계를 수행한다.
따라서, 먼저 순전파를 통해 네트워크가 예측을 출력(출력층의 출력 결과)하고, 이를 손실함수를 이용해 오차를 계산한 뒤, 역방향으로 거슬러 올라가면서 각 뉴런의 입력값에 대한 손실함수의 편미분을 계산하고(backpropagation), 이를 경사 하강법을 이용해 가중치를 조정하는 방법이 역전파 알고리즘이다.
2.4.1 활성화 함수 (activation function)
역전파 알고리즘이 잘 동작하기 위해서 다층 퍼셉트론(MLP)의 구조에 변화를 주었는 데, 그것이 바로 활성화 함수 부분에서 계단 함수를 시그모이드 함수(로지스틱 함수)로 바꿔준 것이다. 이렇게 활성화 함수를 시그모이드 함수로 바꿔준 이유는 가중치 매개변수를 조정 해주기 위해 그래디언트, 편미분을 계산하게 되는데, 계단 함수는 0을 기준으로 기울기가 없는 직선이므로 그래디언트를 계산하는 것이 의미가 없기 때문이다(0을 기준으로 불연속이기 때문에 미분이 불가능한 이유도 있다). 활성화 함수로는 아래의 그림(출처: cs231n)처럼 로지스틱 함수 외에 다양한 활성화 함수를 사용할 수 있다.

위의 그림에서 ReLU 또한 0에서 연속이지만 첩점(뾰족한 점)이므로 미분이 불가능하다. 하지만 0보다 큰 경우에는 미분을 적용하고 0 이하인 값에는 0을 줌으로써 해결할 수 있다. 또한, ReLU가 성능이 좋을 뿐만아니라 'cs231n' 강의에서는 실제 생물학적으로 시그모이드 보다 그럴듯한 작용을 한다고 한다.
2.4.2 소프트맥스(softmax) 함수
소프트맥스 함수(softmax function)는 출력층에서 주로 사용하는 활성화 함수이며, 식은 다음과 같다.
소프트맥스 함수의 특징은 출력값의 총합이 1이 된다는 것이다. 따라서, 각 출력 뉴런에 대한 소프트맥스의 출력값은 각 클래스에 대응하는 추정 확률값으로 볼 수 있다.

3. tf.estimator를 이용한 DNN 구현
tf.estimator와 keras가 있는데, 이에 대한 자세한 내용은 여기에서 참고하면 된다.
아래의 예제는 tf.estimator의 DNNClassifier 클래스를 이용해 MNIST 숫자 데이터를 분류하는 DNN을 구현한 것이다.
Training
# MNIST Dataset Load!
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
# reshape : 28 x 28 -> 784
X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
# split validation set
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:]
# TF Estimator
feature_cols = [tf.feature_column.numeric_column("X", shape=[28 * 28])]
dnn_clf = tf.estimator.DNNClassifier(hidden_units=[300, 100], n_classes=10,
feature_columns=feature_cols)
# input function
input_fn = tf.estimator.inputs.numpy_input_fn(
x={"X": X_train}, y=y_train, num_epochs=40, batch_size=50, shuffle=True)
# training
dnn_clf.train(input_fn=input_fn)...(생략)
INFO:tensorflow:loss = 0.019763667, step = 43201 (0.325 sec)
INFO:tensorflow:global_step/sec: 310.738
INFO:tensorflow:loss = 0.0010194365, step = 43301 (0.321 sec)
INFO:tensorflow:global_step/sec: 310.735
INFO:tensorflow:loss = 0.0024939901, step = 43401 (0.326 sec)
INFO:tensorflow:global_step/sec: 314.647
INFO:tensorflow:loss = 0.007205924, step = 43501 (0.314 sec)
INFO:tensorflow:global_step/sec: 311.705
INFO:tensorflow:loss = 0.00799268, step = 43601 (0.322 sec)
INFO:tensorflow:global_step/sec: 314.646
INFO:tensorflow:loss = 0.020351749, step = 43701 (0.318 sec)
INFO:tensorflow:global_step/sec: 308.818
INFO:tensorflow:loss = 0.013508269, step = 43801 (0.323 sec)
INFO:tensorflow:global_step/sec: 296.027
INFO:tensorflow:loss = 0.009314031, step = 43901 (0.339 sec)
INFO:tensorflow:Saving checkpoints for 44000 into
<tensorflow.python.estimator.canned.dnn.DNNClassifier at 0x23442a061d0>
Testing
# Test input function
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"X": X_test}, y=y_test, shuffle=False)
# Test
eval_results = dnn_clf.evaluate(input_fn=test_input_fn)
eval_results{'accuracy': 0.98,
'average_loss': 0.10493586,
'loss': 13.283021,
'global_step': 44000}
4. 텐서플로의 Low-Level API로 DNN 구현
아래의 예제는 위에서 MNIST 분류기를 Estimator로 구현한 것을 이번에는 텐서플로 Low-Level로 구현한 것이다.
5.1 은닉층의 수
1989년 George Cybenko는 뉴런 수만 무한하다면 은닉층 하나로 어떠한 함수도 근사할 수 있다는 것을 밝혔는데, 이를 시벤코 정리(Cybenko's theorem)이라고 한다. 실제로도 많은 문제들이 하나의 은닉층에 뉴런 수만 충분하다면 모델링이 가능하다. 하지만, 심층 신경망(DNN)이 얕은 신경망보다 파라미터 효율성이 훨씬 좋으며 복잡한 함수를 모델링하는 데에 있어 얕은 신경망보다 훨씬 적은 수의 뉴런을 사용하기 때문에 학습 시간이 더 빠르다.
5.2 은닉층의 뉴런 수
위의 MNIST 분류기 예제 코드에서는 은닉층(hidden layer)의 뉴런수를 첫 번째 은닉층(hidden1)은 300개, 두 번째 은닉층(hidden2)은 100개로 구성하였다. 이처럼 은닉층의 뉴런 수는 일반적으로 각 층의 뉴런을 점점 줄여가는 방법으로 모델링한다. 그 이유는 저수준의 많은 특성(ex. 눈, 코, 입)이 고수준의 적은 특성(ex.얼굴 전체) 으로 합쳐질 수 있기 때문이다.
하지만, 요즘에는 모든 은닉층에 동일한 뉴런 수를 사용하며 모델이 오버피팅되기 전까지 점진적으로 뉴런 수를 늘린다. 일반적으로 층의 뉴런 수를 늘리는 것보다 층(layer) 개수를 늘리는 것이 성능이 더 좋아진다.
이처럼 최적의 은닉층의 수와 뉴런 수를 찾기란 매우 어려운 일이다. 따라서 실제 필요한 개수 보다 더 많은 층과 뉴런으로 모델링한 후에 오버피팅 되지않도록 조정해나가는 방식을 사용하는 데 이를 '스트레치 팬츠'(stratch pants) 방식이라고 한다(교재에서는 그 이유를 자신에게 알맞는 바지 사이즈를 찾는 데 시간을 낭비하는 대신, 큰 스트레치 팬츠를 사고 알맞게 줄이는게 더 낫기 때문).
6. 마무리
이번 포스팅에서는 인공 신경망과 텐서플로를 이용해 DNN을 구현하는 방법에 대해 알아보았다. 위의 코드에 대한 전체 코드는 https://github.com/ExcelsiorCJH/Hands-On-ML/blob/master/Chap10-Introduction_to_ANN/Chap10-Introduction_to_ANN.ipynb
'DeepLearning > 개념' 카테고리의 다른 글
| 05-2. 심층 신경망 학습 - 배치 정규화, 그래디언트 클리핑 (2) | 2018.10.10 |
|---|---|
| 05-1. 심층 신경망 학습 - 활성화 함수, 가중치 초기화 (4) | 2018.10.05 |
| 03. 오차역전파 - BackPropagation (0) | 2018.09.12 |
| 02. 신경망 학습 (1) (0) | 2018.09.12 |
| 01. 퍼셉트론 - Perceptron (2) | 2018.09.12 |